Note
Go to the end to download the full example code.
Classify soundtypes with unsupervised learning
Unsupervised learning algorithms search for structures or patterns in a dataset without requiring labels. In the context of ecoacoustics, this approach can be usefull to draw inferences when manual labelling is inaccesible or too expensive. For example, unsupervised learning can be used to estimate the animal acoustic diversity [1], combine human-reasoning and automated procedures to build reference libraries, and find hidden structures in the soundscapes.
In this example, we will use unsupervised learning to automatically annotate multiple sounds in an audio recording. The process follows four main steps. We will (i) find sounds that can be delimited in time and frequency, here defined as regions of interest (ROIs), (ii) characterize ROIs by features in the time-frequency domain using 2D wavelets [2], (iii) use t-SNE, a dimensionality reduction algorithm, to reduce the dimensionality of the data [3], and (iv) a automatically form homogenous groups using DBSCAN [4]. We will use a real audio file recorded with an omnidirectional microphone. This audio has a poor signal-to-noise ratio, which is typical of automated audio recordings.
Dependencies: This example requires the Python package scikit-learn v0.24 or greater.
# sphinx_gallery_thumbnail_path = './_images/sphx_glr_plot_unsupervised_sound_classification_004.png'
Load required modules
import numpy as np
import matplotlib.pyplot as plt
from maad import sound, features, rois
from maad.util import power2dB, plot2d, format_features, overlay_rois
Start by loading an example audio file. We will remove low frequency ambient noise with a lowpass filter and then compute the spectrogram.
s, fs = sound.load('../../data/rock_savanna.wav')
s_filt = sound.select_bandwidth(s, fs, fcut=100, forder=3, ftype='highpass')
db_max=70 # used to define the range of the spectrogram
Sxx, tn, fn, ext = sound.spectrogram(s_filt, fs, nperseg=1024, noverlap=512)
Sxx_db = power2dB(Sxx, db_range=db_max) + db_max
plot2d(Sxx_db, **{'extent':ext})

1. Find regions of interest
To find regions of interest in the spectrogram, we will remove stationary background noise and then find isolated sounds using a double threshold method. Small ROIs due to noise in the signal will be removed.
Sxx_db_rmbg, _, _ = sound.remove_background(Sxx_db)
Sxx_db_smooth = sound.smooth(Sxx_db_rmbg, std=1.2)
im_mask = rois.create_mask(im=Sxx_db_smooth, mode_bin ='relative', bin_std=2, bin_per=0.25)
im_rois, df_rois = rois.select_rois(im_mask, min_roi=50, max_roi=None)
# Format ROIs and visualize the bounding box on the audio spectrogram.
df_rois = format_features(df_rois, tn, fn)
ax0, fig0 = overlay_rois(Sxx_db, df_rois, **{'vmin':0, 'vmax':60, 'extent':ext})

2. Compute acoustic features
The shape_feaures function uses bidimensional wavelets to get the texture and spectro-temporal shape coeficients of each ROI. Wavelets have the advantage of being robust when the signal-to-noise ratio is low, and derive homogeneous descriptors which facilitate the clustering process. The wavelet decomposition is performed on the complete spectrogram, hence the coeficients for ROIs do not vary much even when not the time-frequency bounds are not exact. The centroid features gives an estimate of the median frequency of the ROIs.
df_shape, params = features.shape_features(Sxx_db, resolution='low', rois=df_rois)
df_centroid = features.centroid_features(Sxx_db, df_rois)
# Get median frequency and normalize
median_freq = fn[np.round(df_centroid.centroid_y).astype(int)]
df_centroid['centroid_freq'] = median_freq/fn[-1]
3. Reduce the dimensionality of the features
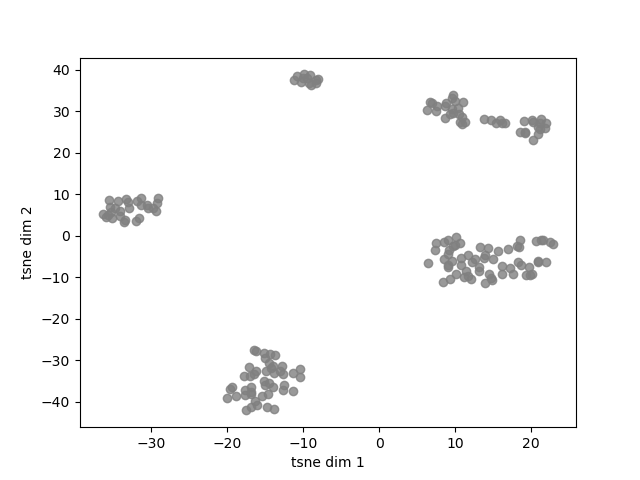
The shape audio features have 26 dimensions. To facilitate the clustering process and visualize the results, it is posible to use non-metric dimensionality reduction algorithm, namely the t-distributed stochastic neighbor embedding (t-SNE), to proyect the data in two dimensions.
from sklearn.manifold import TSNE
X = df_shape.loc[:,df_shape.columns.str.startswith('shp')]
X = X.join(df_centroid.centroid_freq) # add column and normalize values
tsne = TSNE(n_components=2, perplexity=12, init='pca', verbose=True)
Y = tsne.fit_transform(X)
fig, ax = plt.subplots()
ax.scatter(Y[:,0], Y[:,1], c='gray', alpha=0.8)
ax.set_xlabel('tsne dim 1')
ax.set_ylabel('tsne dim 2')
[t-SNE] Computing 37 nearest neighbors...
[t-SNE] Indexed 187 samples in 0.000s...
[t-SNE] Computed neighbors for 187 samples in 0.036s...
[t-SNE] Computed conditional probabilities for sample 187 / 187
[t-SNE] Mean sigma: 0.044609
[t-SNE] KL divergence after 250 iterations with early exaggeration: 49.980255
[t-SNE] KL divergence after 1000 iterations: 0.272204
4. Cluster the ROIs into homogeneous groups.
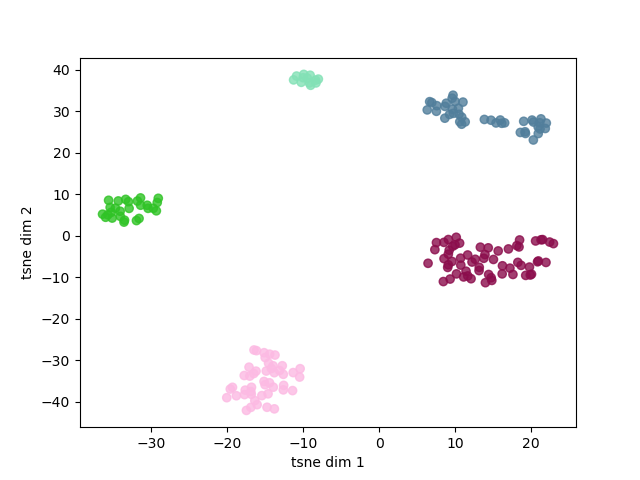
In the above plot it is possible to observe how sounds are aggregated. It is posible to group these samples rapidly and objectively using a clustering algorithm. Here, we will use DBSCAN, a simple algorithm that allows to find core samples with high density and expands clusters from them. This algorithm has the advantage to find automatically the number of clusters and can cope with unbalanced classes.
from sklearn.cluster import DBSCAN
cluster = DBSCAN(eps=5, min_samples=4).fit(Y)
print('Number of soundtypes found:', np.unique(cluster.labels_).size)
Number of soundtypes found: 5
Visualize the clustering results
from maad.util import rand_cmap
fig, ax = plt.subplots()
ax.scatter(Y[:,0], Y[:,1], c=cluster.labels_, cmap=rand_cmap(5 , first_color_black=False), alpha=0.8)
ax.set_xlabel('tsne dim 1')
ax.set_ylabel('tsne dim 2')
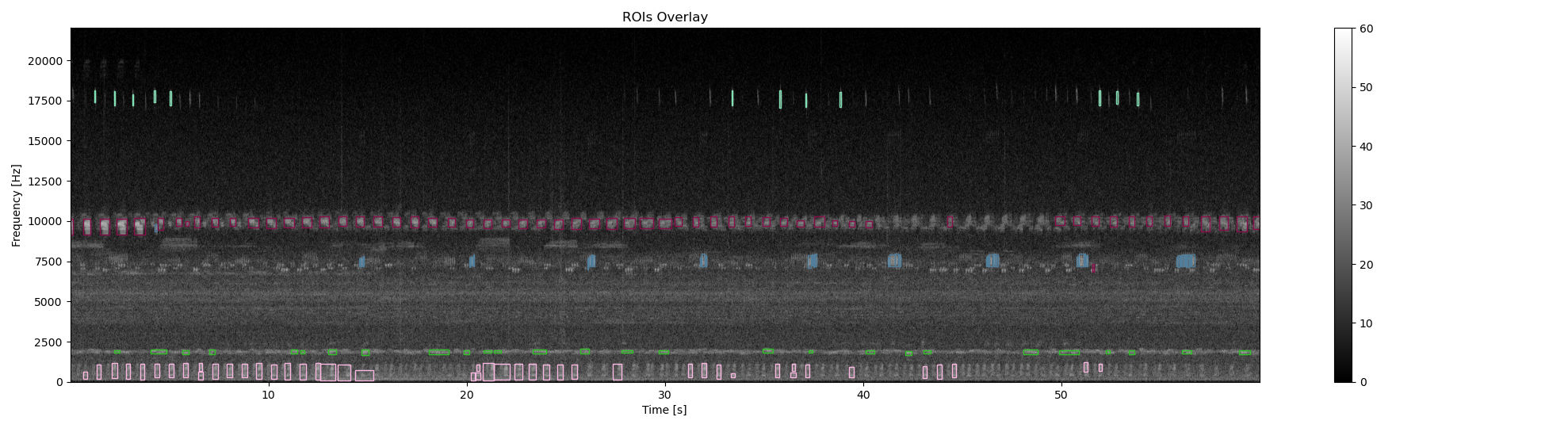
# Overlay bounding box on the original spectrogram
df_rois['label'] = cluster.labels_.astype(str)
ax0, fig0 = overlay_rois(Sxx_db, df_rois, **{'vmin':0, 'vmax':60, 'extent':ext})
References
Ulloa, J. S., Aubin, T., Llusia, D., Bouveyron, C., & Sueur, J. (2018). Estimating animal acoustic diversity in tropical environments using unsupervised multiresolution analysis. Ecological Indicators, 90, 346–355. https://doi.org/10.1016/j.ecolind.2018.03.026
Sifre, L., & Mallat, S. (2013). Rotation, scaling and deformation invariant scattering for texture discrimination. Computer Vision and Pattern Recognition (CVPR), 2013 IEEE Conference On, 1233–1240. http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=6619007
Maaten, L. van der, & Hinton, G. (2008). Visualizing data using t-SNE. Journal of Machine Learning Research, 9(Nov), 2579–2605.
Ester, M., Kriegel, H.-P., Sander, J., & Xu, X. (1996). A density-based algorithm for discovering clusters in large spatial databases with noise. Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining, 96(34), 226–231.
Total running time of the script: (0 minutes 6.392 seconds)